Открыта регистрация на митап Op!DevOps!
Оригинал статьи на habrahabr: https://habrahabr.ru/company/pt/blog/310584/ (ссылка на регистрацию внизу статьи)
О пользе внедрения DevOps уже написано множество статей на Хабре и других ИТ-ресурсах, и она не ставится под сомнение. Это понятно: творческому беспорядку с подчас неочевидными зонами ответственности «обычной» разработки, где разные люди отвечают за код, бранчи, тестовые стенды, сборку и деплой и не очень-то хотят лезть на «поляну» коллег, противопоставляется высокий уровень организации.
В компаниях с внедренным DevOps разработчики обладают большей поддержкой и могут более эффективно работать.

Но мало просто захотеть работать «правильно», нужно еще каким-то образом к этому прийти. А здесь все совсем не так просто.
Нельзя просто так взять и развить DevOps (с)
Точнее можно, но легко этот процесс может пройти только в небольших компаниях, где разрабатывается один-два проекта, или когда во всех командах изначально присутствует высокий уровень культуры разработки. Но как быть внутренним стартапам, где идея нередко обгоняет физические и технические возможности компании?
Когда мы в Positive Technologies решили развивать DevOps, то столкнулись с десятками команд, которые работали над проектами как публичными, так и непубличными. Команды сильно отличались по размеру, использовали разные релизные модели и технологический стек. Все это не позволяло создать решение по принципу one size fits all.
При этом ресурсы всегда ограничены и их не хватало на введение подходов DevOps в рамках каждой команды и проекта. Нужен был какой-то новый подход. И вот что мы придумали.
Первые шаги
Нам был необходим набор элементарных практик DevOps, которые мы могли бы быстро адаптировать под задачи любого проекта. Для этого было нужно разработать шаблоны сборочных, деплойных и тестовых конфигураций, обеспечить масштабирование проектов для множества git-веток отдельных компонент, а также большого числа самих компонент и их версий.
Мы сумели решить эти задачи путем перевода инфраструктуры Continuous Integration на использование связки из нескольких инструментов:
- TeamCity — cистема организации Continuous Integration;
- GitLab — система хранения исходного кода компонент продуктов;
- Artifactory — система хранения собранных бинарных версий компонент и продуктов, кеширующая прокси внешних репозиториев для различных пакетных менеджеров (nuget, npm, pip, rails).
В ходе многочисленных экспериментов на реальных проектах была разработана иерархия проектов TeamCity и типовой интерфейс для всех проектов в этой системе.
Подробно были проработаны процессы:
- сборки и деплоя на тестовые стенды;
- запуска функциональных и иных тестов;
- назначения меток качества пакетам (тестовый, стабильный, готовый для распространения заказчикам);
- публикации релизных сборок на серверы обновления;
- доставки сборок и обновлений на продакшн и многие другие.
По клику картинка откроется в полном размере
Что в итоге
Все это хорошо, но оставались вопросы по внедрению DevOps во все проекты компании.
А что если объединить несколько выделенных специалистов с различными профильными знаниями в одну группу, которая сможет решать DevOps-задачи всей компании?
Так появилась идея создания «пожарной команды». Теперь вместо того чтобы придумывать автоматизацию с нуля для каждого проекта самостоятельно, работающие над ним сотрудники могут «заказать» сервис DevOps.
В итоге мы смогли в разы сократить затраты на обучение и запуск работы по новой методологии, а также снизить количество возможных ошибок.

Тема внедрения DevOps крайне интересна, здесь возможны различные подходы. И крайне важно встречаться и делиться опытом. Обычно такие мероприятия называют митапами.
Мы собираемся провести по сути нечто похожее, но не совсем в обычном формате: мы хотим собрать «девопсов» и разработчиков в непринужденной атмосфере, чтобы в режиме фаст-трека рассказать историю построения нашего собственного DevOps и послушать вас, тех, для кого мы это делали: разработчиков, автоматизаторов и тестировщиков.
Ждем вас на Op!DevOps! в пятницу, 7 октября с 15:00 до 19:00 в Blacksmith Irish Pub
Мероприятие бесплатное, но количество мест ограничено, поэтому для участия нужно зарегистрироваться. Для этого перейдите по ссылке.
Программа мероприятия
№ | Тема доклада | Докладчик | Краткие тезисы |
|---|---|---|---|
| Первый блок докладов | |||
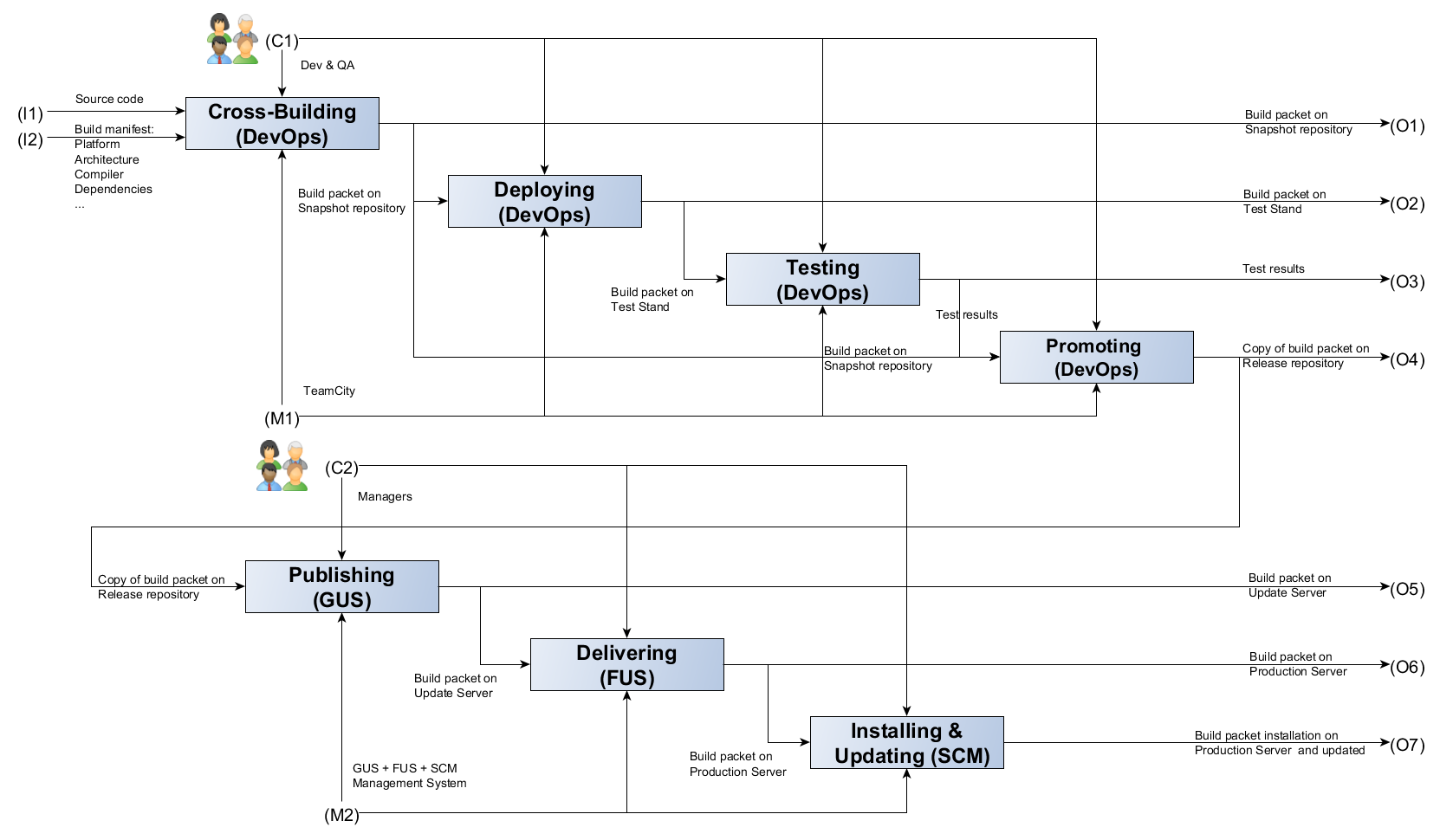
| 1 | Модель системы Continuous Integration в компании Positive Technologies | Тимур Гильмуллин | 1) Первоначальные типовые схемы, предлагаемые DevOps для всех проектов компании: Build — Deploy — Testing — Promote. 2) Реализация схемы на примерах наших проектов в TeamCtiy. 3) К чему мы пришли. Общая схема Continuous Integration: Build — Deploy — Testing — Promote — Publishing — Delivery — Install & Update |
| 2 | SupplyLab — публикация, доставка, развертывание, лицензирование | Александр Паздников | 1) Организация открытой системы управления полным циклом доставки, развертывания и лицензирования до Заказчика. 2) Проектирование системы публикации, доставки, развертывания и лицензирования — SupplyLab. |
| 3 | Общая концепция системы развертывания серверного окружения на базе SaltStack | Дмитрий Мирошниченко | 1) Проектирование системы обновлений. 2) О SaltStack. 3) Реализация update-сервера и примеры. |
| 4 | Инструментарий для создания дистрибутивов продуктов | Владимир Селин | 1) Что такое дистрибутив большого продукта? 2) Проблема: знаниями о процессе установки продукта владеет малое число людей. 3) Шаблоны + DSL — решение всех проблем! |
| Второй блок докладов | |||
| 5 | Организация workflow в трекере TFS | Алексей Соловьев | 1) TFS как трекер: краткий обзор возможностей. 2) Структура типового Workflow: базовые элементы. 3) Сложности кастомизации WorkFlow в TFS. |
| 6 | vSphereTools — инструмент для автоматизации работы с vSphere | Тимур Гильмуллин | 1) VIX API против pysphere. 2) vSphereTools — это набор скриптов от DevOps для поддержки работы с vSphere и виртуальными машинами. 3) Описание инструмента, его достоинства и недостатки, возможные доработки. |
| 7 | Интеграция TeamCity и сервера символов | Алексей Соловьев | 1) Что такое сервер отладочных символов, его предназначение. 2) Отладочная информация (отладочные символы) — информация, которую генерирует компилятор на основе исходных кодов. Содержит информация об именах файлов исходников, переменных, процедур, функций. 3) Сервер отладочной информации — сервер, основное предназначение которого — хранение отладочной информации, ее идексирование и предоставление доступа. |
| 8 | Инструменты для проведения конкурентного анализа программных продуктов. | Владимир Софин | 1) Что такое конкурентный анализ (КА) программных продуктов? 2) Методика и этапы КА. 3) Сложности реализации различных этапов КА. 4) Инструменты для автоматизации КА. |
| Третий блок докладов | |||
| 9 | Нейронечеткая классификация слабо формализуемых данныхю | Тимур Гильмуллин | 1) Проблемы автоматизации классификации слабо формализуемых (нечетких) данных. 2) Нечеткие множества и нечеткие измерительные шкалы. 3) Моделирование нейронной сети для классификации данных. 4) Инструмент FuzzyClassificator и его внедрение в Компании. 5) Автоматизация классификации данных на базе TeamCity. |
| 10 | От простого к сложному: автоматизируем ручные тест-планы | Сергей Тимченко | 1) Смотрим по сторонам — обычный процесс авто-тестирования. 2) Убираем лишнее — реалистичный целевой процесс. 3) DataDrivenTesting — создание спец. инструментов для конкретных сценариев. 4) RobotFramework — что делать, если простых сценариев слишком много. |
| 11 | Система мониторинга Zabbix в процессах разработки и тестирования. | Алексей Буров | 1) Система мониторинга ресурсов различных отделов. 2) Шаблоны и роли серверов, разграничение доступа и зон ответственности. 3) ptzabbixtools — конфигурация мониторинга на целевых серверах. 4) Пример встраивания системы мониторинга в процессы разработки/тестирования. |
| 12 | Автоматизация нагрузочного тестирования в связке LMeter + TeamCity + Grafana | Иван Останин и Сергей Тихонов | 1) Описание старого процесса сора данных о тестах: как было до, что хорошего, что плохого. 2) Influxdb, как хранилище time-series данных. 3) Zabbix — мониторинг нагрузочных стендов: Windows и Linux-агенты, активный сбор данных, autodiscovery виртуальных машин в esx. 4) Grafana, как способ превратить графики и дашборды в конфетку. 5) Автоматизация нагрузки от пользователей через web-UI при помощи Jmeter, отображение статистики в реальном времени, CI Teamcity. |
| Четвертый блок докладов | |||
| 13 | Пакетный менеджер CrossPM: упрощаем сложные зависимости | Александр Ковалев | 1) Сложности при распутывании перекрестных и вложенных зависимостей. 2) Пакетный менеджер CrossPM. Его возможности и примеры использования. 3) Интеграция CrossPM и системы хранения пакетов Artifactory. |
| 14 | Практические рекомендации по использованию системы TestRail | Дмитрий Рыльцов и Алексей Васильев | 1) Цели использования TestRail. 2) Сущности системы TestRail. 3) Особенности проекта. 4) Наше решение. 5) TestRail Integration & Customization. |
| 15 | TeamPass — управление разграничением доступа к сервисным паролям в команде | Дмитрий Мирошниченко | 1) Что не устраивло в keepass? 2) Специфика компании. 3) Решение. |
| 16 | Сообщество DevOpsHQ | Александр Паздников | 1) О проекте DevOpsHQ — сообщество инженеров-автоматизаторов. 2) Преследуемые цели. 3) Предлагаемые инструменты. 4) Предлагаемые методики. 5) Готовые решения. |